Gilad Lotan of SocialFlow introduces us to the recently popular world of data visualization. Is it actually interesting, and is it advancing the stories we’re telling?
Tarek Amr [1] of Global Voices, is a security engineer in Egypt and begins with an incredibly text-dense slide to demonstrate the importance of communicating in a visual manner. This is the main goal of data visualization: it is the intersection of the data you have, the message you want to deliver, and the visual manner in which you deliver it. Visualizations present complex information quickly and clearly, reveal patterns and trends, are easily understood, and ideally, are beautiful and engaging.
Egypt is new to (uncorrupted) political elections, so Tarek created a graph of the various parties’ position on the political spectrum:

Jacepo Carbonari analyzed the parties’ policy positions with much more data and created a denser version of the political graph [2].
 Following the election, Morsi’s own website published a fairly simple map of the results using Michael Geary’s results-gadget.js [3], which gave the impression that Morsi dominated the election. Someone else created a more nuanced map showing the actual percentages of the vote.
Following the election, Morsi’s own website published a fairly simple map of the results using Michael Geary’s results-gadget.js [3], which gave the impression that Morsi dominated the election. Someone else created a more nuanced map showing the actual percentages of the vote.
Data visualization can be as simple as a status bar. A group created a gauge, called Morsi Meter [4] in the spirit of PolitiFact’s Obameter [5], to measure Morsi’s progress fulfilling the promises he made during the campaign.
Tarek’s DataViz Lifecycle:
1. Data acquisition is the process of sampling signals and gathering information.
2. There’s also collaborative data collection and analysis, which was collected with Google Docs.
3. This data was then visualized with the Results gadget and infographs.


Kepha Ngito (@ngitok [6]) is director at Map Kibera [7] (@mapkibera [8]). They gather data pertinent to their community, map it using GIS technology, and present it in the form of a map. Kibera is not just a geographic location. It represents marginalized peoples who don’t even exist on official maps. The government has no reason to provide services to people it does not see on a map.

Kibera is home to around 250,000 people across only 2.5 square kilometers. And yet, on Google and other maps, Kibera was completely blank. A single pin sits over a blank white area labeled as forest.
Thirteen Kibera youth made the first map of Kibera, collecting location information about water points, medical clinics, public latrines, informal schools, churches, mosques, video shops, salons, community organizations, and other civic places. The information is all available for free [9] on OpenStreetMap.
The presentation of this information is the most important step, Kepha says. The perspective this information provides is the critical aspect. Today, the Kibera map begins to resemble the incredibly dense community that is actually present.
The group is now finalizing another map. They lose sleep over decisions about what points of interest to include and leave out, because only so much information can be displayed in such a small amount of space.
The group also creates civic media. Voice of Kibera [10] is an Ushahidi install designed to collect citizen reporting in Kibera. Residents can directly crowdsource news that wouldn’t ordinarily be covered by the mainstream media.
Kibera News Network [11] is a video news project, because the team understands that media must not only contain information, but also present it in a visual way. They’ve been uploading FlipCam videos to their YouTube channel [12] since 2010, and also screening the videos to residents so people understand what’s taking place in their neighborhoods regardless of internet access. Entertainment is an important part of life in the slums. There’s probably a video hall screening football in every neighborhood of Kibera. And film is as much an escape for residents of Kibera as it is for people living everywhere else.
The group has branched into thematic mapping, designing specific maps around health, education, security, and water sanitation. The security map has allowed the Nairobi police to patrol more deeply into the slum than they previously had, because the map removed some of their fears.
They replicated the map-making process in Mathare, another major slum in Nairobi. Again, they took Google’s almost completely blank depiction of the community and populated it with a much finer-grained version of reality. The Mathare Valley blog [13] also helps expose the reality of Mathare to the world.
Nathan Matias [14] (@natematias [15]) from MIT’s Center for Civic Media [16] shifts gears to using the data to learn lessons, in addition to visualizing them. He started in Ethan Zuckerman’s Participatory News Class [17] by scraping news stories for Twitter accounts mentioned. His classmate Chi-Chu Tschang [18] used the approach to create a Twitter list of people talking about Hong Kong, and was actually able to detect an emerging story before the mainstream media.
This led Nathan to consider which voices are truly represented in the media. He took 20 years’ worth of data from New York Times and attempted to analyze the bylines and run them against databases of baby names over the same time period. He can now see who’s writing stories, as well as count pronouns to track content gender. Winter articles in the Style section of New York Times tend to cover only one gender or the other, while in the summer, the two genders appear in articles together much more frequently. It appears we pay closer attention to the opposite sex during warmer months.
 [19]
[19]
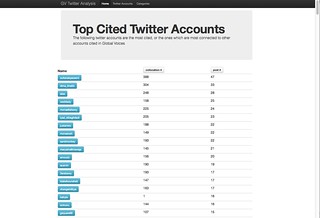
Nathan has shifted his focus to Global Voices. Looking at GV English, he scraped all of the Twitter accounts listed on each blog post, and built a social browser to help you explore these peoples’ reach, as well as their connections to other people.
 [20]
[20]
You can deep dive into a single topic, like GV posts about Mexico, and see volume by week, or the network graph of people cited in the blog posts. He’s curious about whether the same people are frequently cited, or if there’s higher diversity, with more nodes and denser edges. He’s ranked Global Voices’ blog posts by the number of voices they include. Nathan did all of this to figure out what the stories are, and would love to explore further with Global Voices bloggers and editors.
Marek Tuszynski (bio [21]) of Tactical Technology Collective [22] says that data visualization comes down to three steps:
1. Get the point:
We need data for advocacy work, and then we use vehicles that people emotionally engage with: metaphor, subversion, humor, shock, or contrast. Data needs these vehicles to speak to people. Emotions help expose.
2. Get the picture:
We use animation and a storyline to explain what’s relevant about the data. It’s about understanding. What would a sandwich cost if it was priced at the same markup of bottled water? We can provide context and put things into perspective.
3. Get the details:
Most of the time, more information results in more confusion. It’s rare that we can provide the right level of information while creating a minimal level of confusion. The details allow people to explore.
Visualization can be an opening point to bring people to the data and get them intrigued enough to explore it. Or, the data can bring it home, and make the data relevant to your life, like Map Kibera. Or, data can be a process of collaboration, where you contribute data and help form the story.
Data’s most useful for internal purposes, Marek says. Network maps expose influential actors, but need to be translated into clearer versions for people to better understand. We’ve been communicating the idea behind data and visualizing it for many years, but only recently have we had the tools we need to provide the details in a compelling way.
Marek points us to resources at tacticaltech.org [23], Drawing By Numbers [24], a collection of free and open source visualization services, and the recently launched Tactical Studios [25]. You can get in touch with them at @info_activism [26].
Gilad Lotan [27] covers Israel for GV, and is also a data scientist at SocialFlow [28]. Many of their internal data viz tools provide strong understandings and aren’t published.
You don’t always need beautiful graphs. Gilad has profiled various types of events by the frequency of words over time on Twitter. A simple mapping of the words Starbucks, coffee, morning, and tired appearing across Twitter show a reflection of our lives in the data. We drink coffee in the morning. We see spikes of the word ‘hangover’ on Saturday and Sunday mornings, following previous spikes in the appearance of the word ‘party’. ‘Beer’, meanwhile, is pretty constant across time.
 [29]
[29]
We can analyze language usage on Twitter, and see timezone-based peaks with English and Japanese, while Spanish is more constant around the world.
The typical sports event shows high interest at the beginning of a game, followed by a lull, and then very high rates as the game concludes. Games tend to follow this activity profile.
We can also look at social movements, like MarchaAntiEPN [30], and see their reach versus popular culture events like True Blood and the Tony Awards. The shape of the curve itself can tell us what type of events it represents.
The hashtag #blamethemuslims [31] was started by a Muslim woman, Sanum Ghafoor [32]. She lives in England fed up by the media blaming Muslims for the recent shooting in Norway (which turned out to be perpetrated by a Norwegian). Is your watch broken? #blamethemuslims. The snarky meme took off in their neighborhood, died down that night, and then took off worldwide the next day. The hashtag exploded, but lost its original ironic context and upset many people who saw it trending on Twitter.
The shape of the graph also reveals the difference between the organic growth of #blamethemuslims versus a botnet, AJ Discala, which has a clearly artificial spike in traffic. Breaking news is another activity we can model. Whitney Houston’s death spikes suddenly on Twitter.
 [33]
[33]
The #occupy hashtag caused widespread discussion of how Twitter’s trending topics work, with many alleging censorship. But by looking at what else is happening on the network, we can see that sillier hashtags about Kim Kardashian’s wedding and #ICantRespectYouIf seriously outperform the Occupy protests. Twitter’s algorithm favors new, spiking content over gradually growing trends like #occupy.
Gilad’s interested in how information spreads, especially on Twitter. A coworker of his, who isn’t particularly influential on Twitter (but is a Red Sox fan) started #cheeringfortheYankeesislike. SocialFlow built a visual replay that shows the acceleration of the meme over time. The early trickle becomes a complete flood as a couple of influential Twitter users pick it up. A tree map visualization allows Gilad to go back and see which users contributed most to the hashtag’s virality. In this case, we can thank @jaketapper [34].
Marketers of all kinds are obsessed with how we reach the influencers, but we already know who they are. What these tree maps show is the actual paths we can use to reach them using a natural path.
What techniques do you have to boil down a lot of data into a story?
Kepha focuses on the quality of the data and people’s interest in the information you’re collecting. People in Kibera care about the schools their children go to, the dumping sites in their neighborhoods. Software is necessary, but the end product should be so simple that you can’t tell there was a complicated process involved.
Marek says that in advocacy work, it matters who you’re talking to, what you want to tell them, and what you want them to do as a result. Your data and how you present it should stem from the answers to these questions.
Nathan’s work with Global Voices gives people an opportunity to put themselves into the data, and explore from there. BBC’s visualization of The World at 7 Billion [35] and other successful online data viz projects begin with the individual.
Did balkanization of #occupy hashtags hurt its trending ability?
Yes, that was one reason. But also its slow build over time, rather than acute spike. (More on the SocialFlow blog [36]).
Zeynep: It’s interesting that the Twitter algorithm rewards spikes rather than slow builds, because we critique the same thing about professional journalism: they cover when planes crash, not when they take off.
Gilad: It’s actually a fairly simple algorithm, using Tf*idf [37], which is used by a variety of services and news recommendation sites to create hot lists (including Tumblr). It’s just the simplest method to get the best list of conversations out of the massive amount of data.
Ethan: We have incredible strength and interest in this community around data viz. Let’s ask the audience here: What do we want to know about Global Voices and citizen media more generally that data viz could tell us?
Ivan: We want to know if the thing we say we’re doing is what we’re actually achieving. With the Twitter network maps, are we actually engaging a diverse group of voices? If we’re only following a small group of people, we should be doing so intentionally, and write about it.
A lot of people at GV are working on social justice issues — how can data viz help there? Have there been cases where it created impact on the ground?
Marek: That’s the wrong question. There’s no way the image can create change. It can influence groups to act on and organize for change. But in the whole spectrum, the image is one piece. It can help or damage your efforts.
Gilad: We’re very focused on traffic, but I think we could do more to show our true influence and reach beyond website hits.
Deen Freelon: How can people get started in data viz? I see two barriers to entry: technical aptitude (knowing about APIs, databases, and visualization tools) and the proprietary nature of so much of this data. For Twitter analysis, you really need full firehose access, which Twitter charges for. The regular API doesn’t get you all of the tweets. So you need money or inside access for many datasets, in addition to technical aptitude.
Tarek notes that there are many free tools online that make it easier to create visualizations. But mainly we need to think about what we want to create and how to connect people with the information.
Nathan draws a distinction between the large dataset analyses and practical applications of internal data that organizations. Rahul Bhargava runs DataTherapy.org [38] to help organizations learn to do exactly this.
Rob Faris: There’s advocacy and bias in all sorts of information. Visualization is particularly susceptible to these claims, because by nature it’s a deduction of large amounts of data, and there’s a black box nature to this work. Are there emerging standards of the ethics involved?
Tarek says it comes back to the credibility of the individuals producing the work, as with anything else. Nathan says that responsible players should include the caveats with their work and explain how it was produced. His work, for example, may have included Global Voices draft posts. Tarek points to the Open Journalism and Open Science movements, where authors publish their spreadsheets and data with their work to allow others to re-run and challenge their work. Gilad sees little actual hunger for methods sections in blog posts — people just want the story.